4-17%。这是过去一个月里,Claude Code 的 prompt cache 读取率。正常水平是 97-99%。
这意味着,当你恢复一个之前的会话时,Claude Code 没有复用之前已经处理过的上下文,而是每次都从头处理全部内容,消耗的额度是正常情况的 10 到 20 倍。你以为自己在延续一段对话,实际上每次都在重新开始一段全新的、全价的对话。
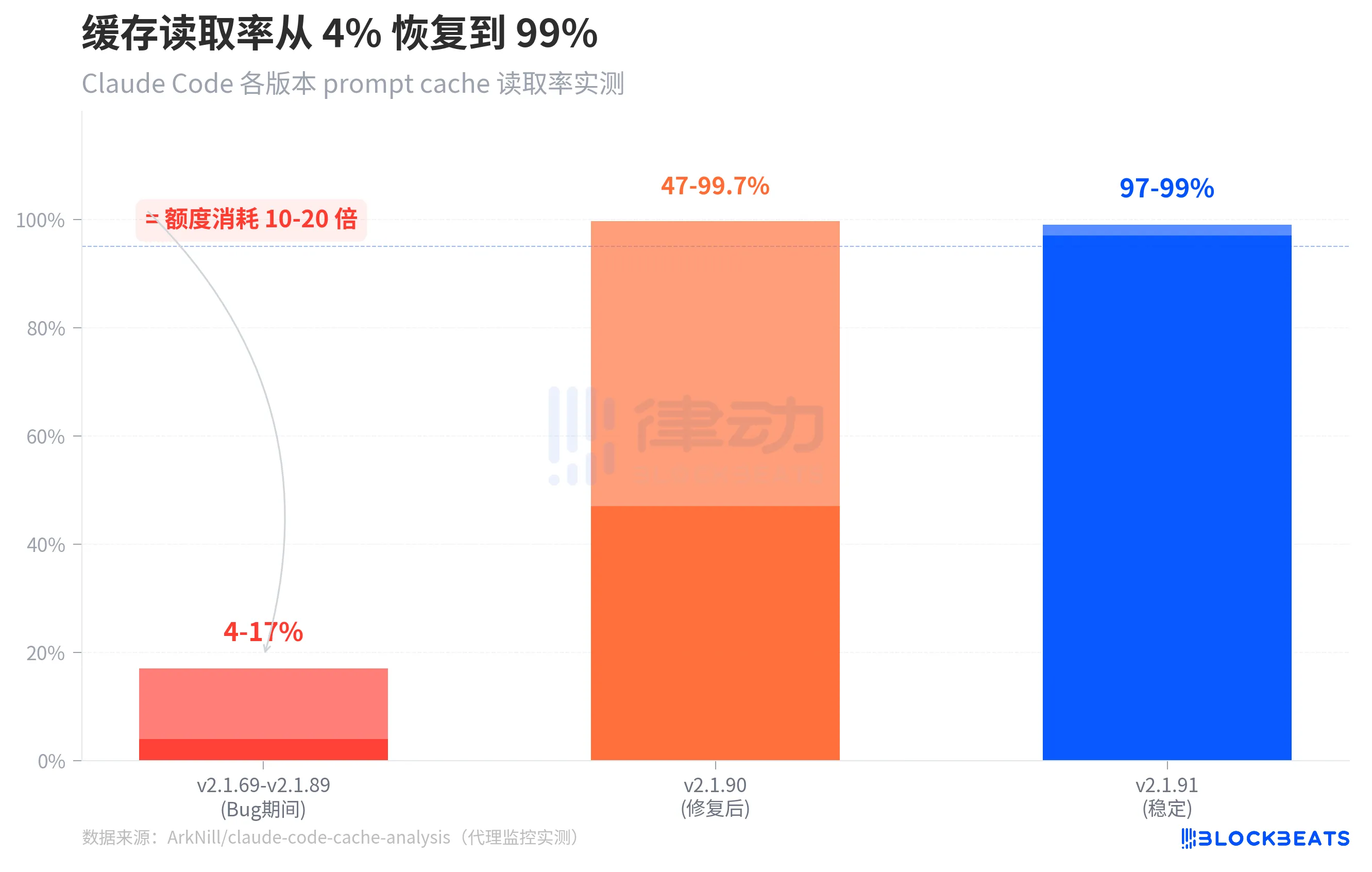
上图展示了三个阶段的缓存读取率对比。v2.1.69 至 v2.1.89 期间(即 Bug 存在期),standalone 版本的缓存读取率仅有 4-17%。v2.1.90 修复了其中一个关键 bug 后,冷启动缓存读取率回到 47-99.7%。到 v2.1.91,稳定运行下的缓存读取率恢复到 97-99%。
值得注意的是图表中的一个细节:v2.1.90 的范围跨度很大(47% 到 99.7%),这是因为会话刚恢复时仍需「预热」缓存,前几轮的命中率偏低,但很快回到正常水平。而在 Bug 版本中,这个预热永远不会发生——缓存读取永远停留在系统提示词的 14,500 个 token 上,所有对话历史每次都按全价计费。
28 天,20 个版本
这个 bug 不是某次更新引入、下次更新修复的那种。据 npm registry 的发布记录,引入 bug 的 v2.1.69 发布于 3 月 4 日,修复 bug 的 v2.1.90 发布于 4 月 1 日。中间隔了 28 天,横跨 20 个版本。
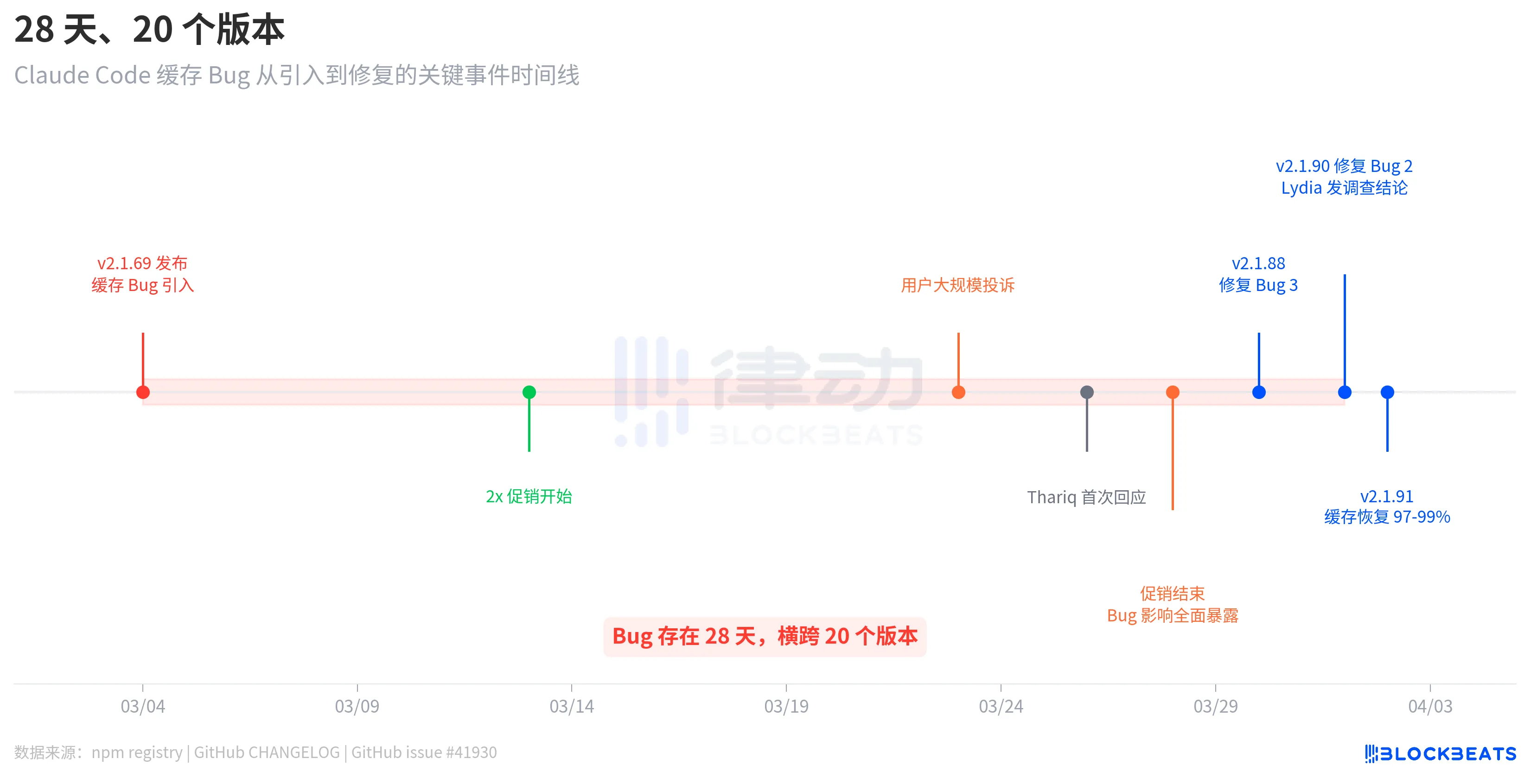
时间线揭示了一个耐人寻味的细节。3 月 4 日 bug 引入后,用户并没有立刻大规模投诉。直到 3 月 23 日,投诉才集中爆发,中间隔了将近三周。原因是,据 GitHub issue #41930 的梳理,3 月 13 日至 28 日 Anthropic 曾上线 2 倍额度促销(off-peak 时段翻倍),这在客观上掩盖了 bug 的影响。促销结束后,缓存 bug 的消耗回到正常计费基线,用户的额度瞬间「蒸发」。
Anthropic 的回应来得并不快。3 月 26 日,也就是用户投诉爆发三天后,工程师 Thariq Shihipar 在个人 X 账号上宣布,高峰时段(工作日 5am-11am PT)的限额已收紧。3 月 30 日,Anthropic 在 Reddit 上承认「用户触达限额的速度远超预期」,称已列为团队最高优先级。直到 4 月 1 日,团队成员 Lydia Hallie 才发布了正式的调查结论。
整个过程中,Anthropic 没有发布任何博客文章、没有发送邮件通知、没有更新状态页。所有官方沟通仅通过工程师的个人社交媒体帖子和少数 Reddit 评论完成。
你付了多少钱,能用多久?
GitHub issue #41930 汇集了数百条用户报告。最极端的案例是一位 Max 20x 订阅用户($200/月),他的 5 小时滚动窗口在 19 分钟内就完全耗尽。Max 5x 用户($100/月)报告 5 小时窗口在 90 分钟内用完。据 The Letter Two 报道,还有用户称一条简单的「hello」就消耗了 13% 的会话配额。一位 Pro 用户($20/月)在 Discord 上说,他的额度「每周一就用完了,周六才重置」,30 天里只有 12 天能正常使用。

据 ArkNill 的基准测试,在 bug 版本 v2.1.89 上,Max 20x 计划的 100% 配额在约 70 分钟内就会耗尽。他还测算了单次 --resume 操作对一个 500K token 上下文会话的额度成本,约 $0.15,因为系统会完整重放整个上下文。
「你拿的方式不对」
Lydia Hallie 的调查结论确认了两点,一是高峰时段限额确实已收紧,二是 100 万 token 上下文的会话消耗增大。她称团队修复了一些 bug,但强调「没有任何一个 bug 导致了多收费」。
随后她给出了四条省量建议:
1. 用 Sonnet 4.6 而非 Opus(Opus 消耗速度约为两倍);
2. 不需要深度推理时降低推理强度或关闭 extended thinking;
3. 闲置超过一小时的长会话不要恢复,重新开一个;
4. 设置环境变量 CLAUDE_CODE_AUTO_COMPACT_WINDOW=200000 限制上下文窗口大小。
没有提及任何形式的限额重置或补偿。
AI 播客主持人 Alex Volkov 将这份回应概括为「你拿的方式不对」(You're holding it wrong),指出 Anthropic 自己把 100 万 token 上下文设为默认、把 Opus 作为旗舰模型推广、把 extended thinking 作为卖点,现在却建议付费用户不要使用这些功能。
「没有多收费」的说法也与 Claude Code 自己的更新记录存在张力。就在 Lydia 发布回应的前一天,v2.1.90 修复了一个自 v2.1.69 起存在的缓存回归 bug:使用 --resume 恢复会话时,本应命中缓存的请求会触发完整的 prompt cache miss,按全价计费。Lydia 的回应中没有提及这个已确认的计费异常。
 文 | Sleepy.md
文 | Sleepy.md
在那个按字收费的电报年代,笔墨即是金钱。人们习惯将万语千言浓缩至极致,「速归」抵得过一封长信,「平安」是最重的叮咛。
后来,电话牵进了家门,但长途费按分秒计费。父母的长途电话总是言简意赅,正事说完便匆匆挂断,一旦话头稍微延展,心疼话费的念头便会掐断刚冒头的寒暄。
再后来,宽带进家,上网按小时收费,人们盯着屏幕上的计时器,网页一开即关,视频只敢下载,流媒体在当时是个奢侈的动词。每一个下载进度条的尽头,都藏着人们对「连接世界」的渴望与对「余额不足」的忌惮。
计费的单位变了又变,省钱的本能亘古不变。
如今,Token 成了 AI 时代的货币。然而,大多数人尚未学会如何在这个时代精打细算,因为我们还没学会如何在看不见的算法里计算得失。
2022 年 ChatGPT 刚出来的时候,几乎没人关心 Token 为何物。那是 AI 的大锅饭时代,每月花个 20 美元,想聊多少聊多少。
但自从最近 AI Agent 火起来之后,Token 花销变成了每一个用 AI Agent 的人都必须关注的事情。
不同于一问一答的简单对话,一个任务流的背后是成百上千次的 API 调用,Agent 的独立思考是有代价的,每一次自我修正、每一次工具调用,都对应着账单上数字的跳动。然后你会发现你充值进去的钱突然就不够用了,而且你还不知道 Agent 到底都干了什么。
现实生活里,大家都知道怎么省钱。去菜市场买菜,我们知道把带泥的烂叶子择干净再上秤;打车去机场,老司机知道避开早高峰的高架。
数字世界里的省钱逻辑其实也一样,只不过计费单位从「斤」和「公里」,换成了 Token。

在过去,节省是由于匮乏;而在 AI 时代,节省是为了精准。
我们希望通过这篇文章,帮你梳理出一套 AI 时代下的省钱方法论,让你把每一分钱都花在刀刃上。
上秤前,先择掉烂菜叶
在 AI 时代,信息的价值不再由广度决定,而由纯度决定。
AI 的计费逻辑是按它阅读的字数收费。无论你喂进去的是真知灼见,还是毫无意义的格式废话,只要它读了,你就得付钱。
因此,省 Token 的第一个思维方式,就是把「信噪比」刻进潜意识。
你喂给 AI 的每一个字、每一张图、每一行代码,都要付钱。所以在把任何东西交给 AI 之前,记得先问问自己:这里面有多少是 AI 真正需要的?有多少是带泥的烂菜叶?
比如「你好,请帮我...」这种冗长的开场白、重复的背景介绍、没删干净的代码注释,都是带泥的烂菜叶。
除此之外,最常见的浪费,是直接把 PDF 或网页截图扔给 AI。这样的确你自己是省事了,但是 AI 时代的「省事」往往意味着「昂贵」。
一份格式完整的 PDF,除了正文内容,还包含页眉、页脚、图表标注、隐藏水印,以及大量用于排版的格式代码。这些东西对 AI 理解你的问题毫无帮助,但它们全部都要计费。
下次记得把 PDF 先转成干净的 Markdown 文本再喂给 AI。当你把 10MB 的 PDF 变成 10KB 的干净文本时,你不仅省下了 99% 的钱,还让 AI 的大脑运行速度比以前快得多。
图片是另一个吞金兽。
在视觉模型的逻辑里,AI 并不在乎你的照片拍得美不美,它只在乎你占用了多少像素面积。
以 Claude 的官方计算逻辑为例:图片的 Token 消耗 = 宽度像素 × 高度像素 ÷ 750。
一张 1000×1000 像素的图片,消耗约 1334 个 Token,按 Claude Sonnet 4.6 的定价折算,每张图片约 0.004 美元;
但如果把同一张图压缩到 200×200 像素,只消耗 54 个 Token,成本降到 0.00016 美元,差了整整 25 倍。
很多人直接把手机拍的高清照片、4K 截图扔给 AI,殊不知这些图片消耗的 Token 可能足以让 AI 读完大半本中篇小说。如果任务只是识别图片里的文字或者做简单的视觉判断,比如让 AI 识别发票上的金额、阅读说明书里的文字,或者判断图中是否有红绿灯,那么 4K 的分辨率就是纯纯的浪费,把图片压缩到最小可用分辨率就够了。
但输入端最容易浪费 Token 的原因,其实不是文件格式,而是低效的说话方式。
很多人把 AI 当成真人邻居,习惯用社交式的碎碎念去沟通,先丢一句「帮我写个网页」,等 AI 吐出个半成品,再补充细节,再反复拉扯。这种挤牙膏式的对话,会让 AI 反复生成内容,每一轮修改都在叠加 Token 消耗。
腾讯云的工程师在实践中发现,同样一个需求,挤牙膏式的多轮对话,最终消耗的 Token 往往是一次性说清楚的 3 到 5 倍。
真正的省钱之道,是放弃这种低效率的社交试探,一次性把要求、边界条件、参考范例说清楚。少去费力解释「不要做什么」,因为否定句往往比肯定句消耗更多的理解成本;直接告诉它「要怎么做」,并给出一个清晰的正确示范。
同时,如果你知道目标在哪里,就直接跟 AI 说清楚,别让 AI 去当侦探。
当你命令 AI「找一下用户相关的代码」时,它必须在后台进行大规模的扫描、分析与猜测;而当你直接告诉它「去看 src/services/user.ts 这个文件」时,Token 的消耗天差地别,在数字世界里,信息对等就是最大的节约。
别为 AI 的「礼貌」买单
大模型计费有个潜规则很多人没意识到:输出 Token 通常比输入 Token 贵 3 到 5 倍。
也就是说,AI 说出来的话,比你说给它的话要贵得多。以 Claude Sonnet 4.6 的定价为例,输入每百万 Token 仅需 3 美元,而输出则陡然跳升至 15 美元,整整 5 倍的价差。
那些「好的,我已完全理解您的需求,现在开始为您解答……」的礼貌开场白,那些「希望以上内容对您有所帮助」的客套结尾,在真人沟通时是礼貌的社交辞令,但是在 API 的账单上,这些毫无信息增量的寒暄也都是要花你自己的钱的。
解决输出端浪费最有效的手段,是给 AI 立规矩。用系统指令明确告诉它:不要寒暄,不要解释,不要复述需求,直接给答案。
这些规矩只需设定一次,便在每一次对话中生效,是真正「一次投入、永久受益」的理财手段。但在建立规矩时,很多人又陷入了另一个误区:用冗长的自然语言去堆砌指令。
工程师的实测数据表明,指令的效能不在于字数,而在于密度。将一段 500 字的系统提示词压缩到 180 字,通过删掉无意义的礼貌用语、合并重复指令、并将段落重构为简洁的条目化清单,AI 的输出质量几乎毫无波动,但单次调用的 Token 消耗却能骤降 64%。
还有一个更主动的控制手段,那就是限制输出长度。很多人从来不设置输出上限,任由 AI 自由发挥,这种对表达权的放任,往往会导致极度的成本失控。你或许只需要一个点到为止的短句,AI 却为了展现某种「智力诚意」,不由分说地为你生成了一篇 800 字的小作文。
如果你追求的是纯粹的数据,就应当强制 AI 返回结构化的格式,而非冗长的自然语言描述。在承载同等信息量的情况下,JSON 格式的 Token 消耗远低于散文化的段落。这是因为结构化数据剔除了所有冗余的连接词、语气词及解释性修饰,只保留了高浓度的逻辑核心。在 AI 时代,你应该清醒地意识到,值得你付费的是结果的价值,而非 AI 那段毫无意义的自我解释。
除此之外,AI 的「过度思考」也在疯狂蚕食你的账户余额。
一些高级模型有「扩展思考」模式,会在回答之前先进行海量的内部推理。这个推理过程也要计费,而且是按输出的价格来计价的,非常贵。
这种模式本质上是为「需要深度逻辑支撑的复杂任务」设计的。但是大多数人在问简单问题的时候也选择了这个模式。对于不需要深度推理的任务,明确告诉 AI「不需要解释思路,直接给答案」,或者手动关掉扩展思考,也能帮你省不少钱。
别让 AI 翻旧账
大模型没有真正的记忆,它只是在疯狂地翻旧账。
这是很多人不知道的一个底层机制。每次你在一个对话窗口里发出新消息,AI 并不是从你这句话开始理解,而是把你们之前聊过的所有内容,包括每一轮对话、每一段代码、每一份引用文档全部重新读一遍,然后才回答你。
在 Token 的账单里,这种「温故而知新」绝非免费。随着对话轮次的叠加,哪怕你只是追问一个简单的词,AI 背后重读整本旧账的成本也会呈几何倍数增长。这种机制决定了,对话历史越沉重,你的每一句提问就越昂贵。
有人追踪了 496 个包含 20 条以上消息的真实对话,发现第 1 条消息平均读取 14,000 个 Token,每条成本约 3.6 美分;到第 50 条消息时,平均读取 79,000 个 Token,每条成本约 4.5 美分,贵了整整 80%。而且上下文越来越长,到第 50 条时,AI 要重新处理的上下文已经是第 1 条时的 5.6 倍。
解决这个问题,最简单的习惯是:一个任务,一个对话框。
当一个话题聊完,果断开启新对话,不要把 AI 当成一个永远不关机的聊天窗口。这个习惯听起来很简单,但很多人就是做不到,总觉得「万一还要用到之前的内容呢」。事实上,那些你担心的「万一」绝大多数时候是不会出现的,而为了这个万一,你已经在每一条新消息上多付了几倍的钱。
当对话确实需要延续,但上下文已经变得很长时,我们可以利用一些工具的压缩功能。Claude Code 有一个/compact 命令,能把长篇大论的对话历史浓缩成一段简短的摘要,帮你做一次赛博断舍离。
还有省钱逻辑叫 Prompt Caching(提示词缓存)。如果你反复使用同一段系统提示词,或者每次对话都要引用同一份参考文档,AI 会把这部分内容缓存起来,下次调用时只收取很少的缓存读取费用,而不是每次都按全价计费。
Anthropic 的官方定价显示,缓存命中的 Token 价格是正常价格的 1/10。OpenAI 的 Prompt Caching 同样能把输入成本降低大约 50%。一篇 2026 年 1 月发表在 arXiv 上的论文,对多个 AI 平台的长任务进行了测试,发现提示词缓存能把 API 成本降低 45% 到 80%。
也就是说,同样的内容,第一次喂给 AI 要付全价,之后每次调用只要付 1/10。对于那些每天都要重复使用同一套规范文档或系统提示词的用户来说,这个功能能省下大量 Token。
但 Prompt Caching 有一个前提,你的系统提示词和参考文档的内容和顺序必须保持一致,而且要放在对话的最前面。一旦内容有任何改动,缓存就会失效,重新按全价计费。所以,如果你有一套固定的工作规范,就把它写死,不要随意修改。
最后一个上下文管理的技巧,是按需加载。很多人喜欢把所有的规范、文档、注意事项一股脑塞进系统提示词里,理由还是那个「以防万一」。
但这样做的代价是,你明明只是在做一个很简单的任务,却被迫加载了几千字的规则,白白浪费一堆 Token。Claude Code 的官方文档建议把 CLAUDE.md 控制在 200 行以内,把不同场景的专项规则拆分成独立的技能文件,用到哪个场景才加载哪个场景的规则。保持上下文的绝对纯净,就是对算力最高级的尊重。
别开保时捷去买菜
不同的 AI 模型,价格差距巨大。
Claude Opus 4.6 每百万 Token 输入要 5 美元、输出 25 美元,Claude Haiku 3.5 只要 0.8 美元输入、4 美元输出,差了将近 6 倍。让最顶级的模型去干搜集资料、排版格式的杂活,不仅慢,而且很贵。

聪明的用法是把我们人类社会常见的「阶级分工」思维带到 AI 社会,不同难度的任务,交给不同价位的模型。
就像在现实世界里雇人干活,你不会专门去雇一个年薪百万的专家去工地搬砖。AI 也一样。Claude Code 的官方文档里也明确建议:Sonnet 处理大多数编程任务,Opus 留给复杂的架构决策和多步骤推理,简单的子任务指定用 Haiku。
更具体的实操方案是构建「两段式工作流」。在第一阶段,用免费或廉价的基础模型做前期的脏活累活,比如资料搜集、格式清理、初稿生成、简单的分类和归纳。进入第二阶段,再将提炼后的高纯度精华投喂给顶级模型,进行核心决策与深度精修。
举个例子,如果你要分析一份 100 页的行业报告,可以先用 Gemini Flash 把报告里的关键数据和结论提取出来,整理成一份 10 页的摘要,然后再把这份摘要交给 Claude Opus 做深度分析和判断。这种两段式工作流,能在保证质量的前提下,把成本大幅压缩。
比单纯的分段处理更进阶的,是基于任务解构的深度分工。一个复杂的工程任务,完全可以被拆解为数个彼此独立的子任务,并匹配最合适的模型。
比如一个需要写代码的任务,可以让廉价模型先写框架和样板代码,然后只把核心逻辑的部分交给昂贵模型来实现。每个子任务有干净、专注的上下文,结果更准确,成本也更低。
你本来不需要花 Token
前面所有的探讨,本质上都在解决「如何省钱」的战术问题,但一个更底层的逻辑命题被很多人忽视了:这个动作,到底需不需要花 Token?
最极致的节省不是算法的优化,而是决策的断舍离。我们习惯了向 AI 寻求万能的解答,却忘了在很多场景下,调用昂贵的大模型无异于高射炮打蚊子。
比如让 AI 自动处理邮件,它会把每一封邮件都当成独立任务去理解、分类、回复,Token 消耗巨大。但如果你先花 30 秒扫一眼收件箱,手动筛掉那些明显不需要 AI 处理的邮件,再把剩下的交给 AI,成本立刻降到原来的一小部分。人的判断力在这里不是障碍,而是最好用的过滤器。
电报时代的人知道,每多发一个字要多花多少钱,所以他们会掂量,这是一种对资源的直觉感知。AI 时代也一样,当你真正知道每让 AI 多说一句话要多花多少钱,你自然就会掂量这件事值不值得让 AI 来做、这个任务需要顶级模型还是廉价模型、这段上下文还有没有用。
这种掂量,是最省钱的能力。算力越来越贵的时代,最聪明的用法,不是让 AI 替代人,而是让 AI 和人去干各自擅长的事。当这种对 Token 的敏感性内化为一种条件反射,你才真正从算力的附庸,变回了算力的主人。