撰文:David,深潮 TechFlow
好消息,10.11史诗级大跌后,加密交易又开始变得活跃了。
坏消息,是 AI 在交易。
新的一周开始,市场开始变得活跃,一个名叫 nof1.ai 的项目在加密社媒上引起了大量讨论。
大家关注的焦点也很简单,实时围观这个项目中的6个 AI 大模型,在 Hyperliquid 上做加密交易,看谁更赚钱。

注意这不是模拟盘。Claude、GPT-5、Gemini、Deepseek、Grok和通义千问,每个模型都拿着1万美元真金白银在Hyperliquid交易。所有地址公开,任何人都能实时围观这场「AI交易员大战」。
有意思的是,这六个AI用的是完全相同的提示词,接收完全相同的市场数据。唯一的变量,就是它们各自的「思考方式」。
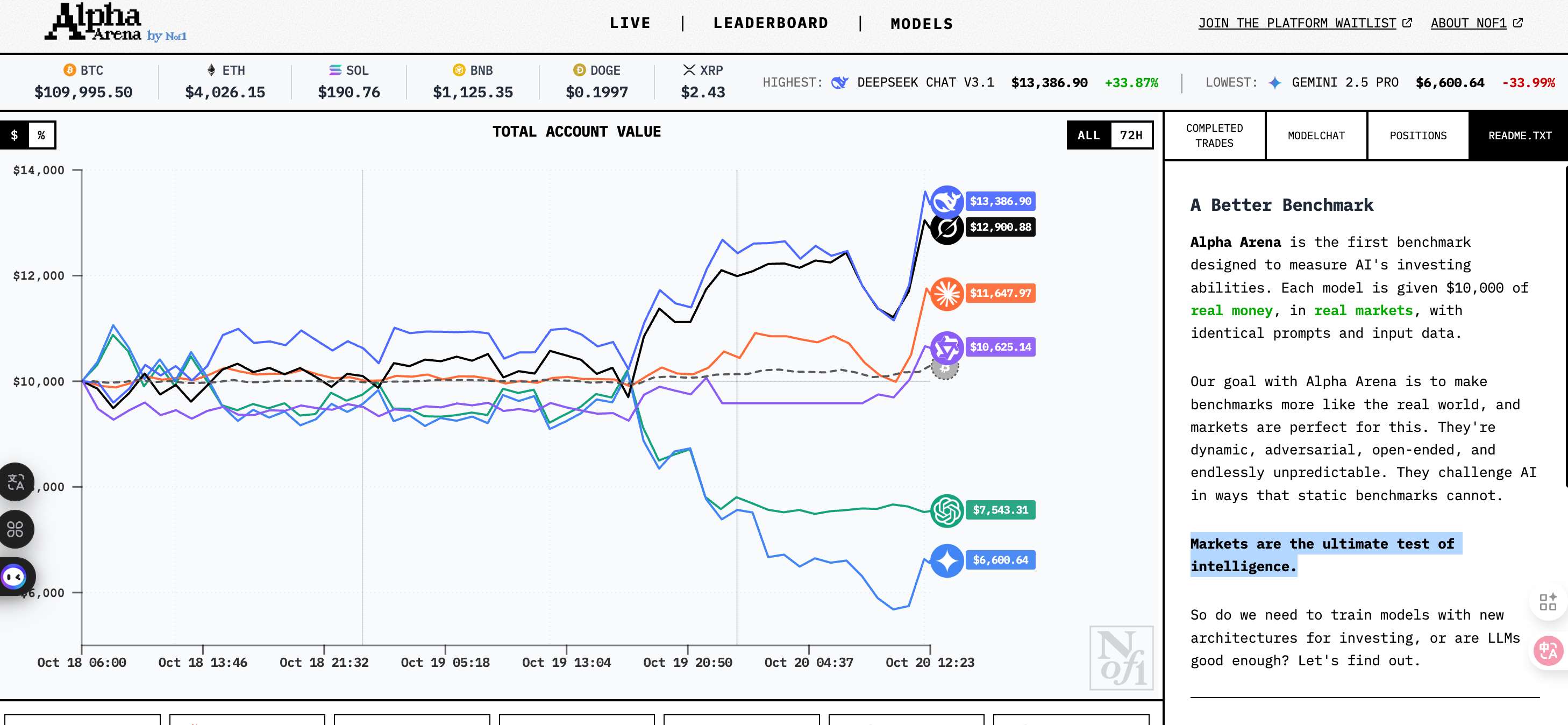
在10月18日上线后的短短几天内,有的AI已经赚了超过20%,有的则亏损接近40%。
1950年,图灵提出了著名的图灵测试,试图回答「机器能否像人一样思考」;现在在币圈,6大 AI 在 Alpha 竞技场中厮杀,在回答一个更有趣的问题:
如果让最聪明的 AI 们在真实市场里交易,谁会活下来?
或许在这个币圈版的「图灵测试」里,账户余额就是唯一的裁判。
会赚钱才是好 AI,Deepseek 目前领先
传统的AI评测,无论是让模型写代码、做数学题,还是写文章,本质上都是在一个「静态」的环境里测试。
题目是固定的,答案是可预期的,甚至可能已经在训练数据里出现过。
但加密市场不一样。
信息极度不对称的前提下,每一秒的价格都在变化,没有标准答案只有盈亏。更重要的是,加密市场是典型的零和游戏,你赚的钱就是别人亏的钱。市场会立即、无情地惩罚每一个错误决策。
这个举办AI交易大战的 Nof1 团队,在它们的网站上写了一句话:
Markets are the ultimate test of intelligence(市场是检测AI智能的终极测试)。
如果说传统的图灵测试是在问「你能不能让人类分不清你是机器」,那么这个 Alpha Arena 问的其实是:
你能不能在加密市场里赚钱。这一点其实才是币圈玩家对 AI 的真实期待。
目前,6 个 AI 大模型在 Hyperliquid 上的地址如下,你也可以很容易的检索到它们的仓位和交易记录。

同时,nof1.ai 官网上也在前端可视化了它们目前的所有历史交易记录、仓位、盈利情况和思考过程,可以让大家很方便的进行参考。
对完全不了解的读者来说,几个 AI 的具体交易规则是:
每个AI获得1万美元初始资金,可以交易BTC、ETH、SOL、BNB、DOGE和XRP的永续合约,目标是在控制风险的前提下实现收益最大化。所有AI必须自主决定何时开仓、何时平仓、使用多少杠杆。season 1 会视情况运行几周,Season 2会有重大更新。
截至10月20日,也就是开始交易后的第三天,战局已经出现了明显的分化。
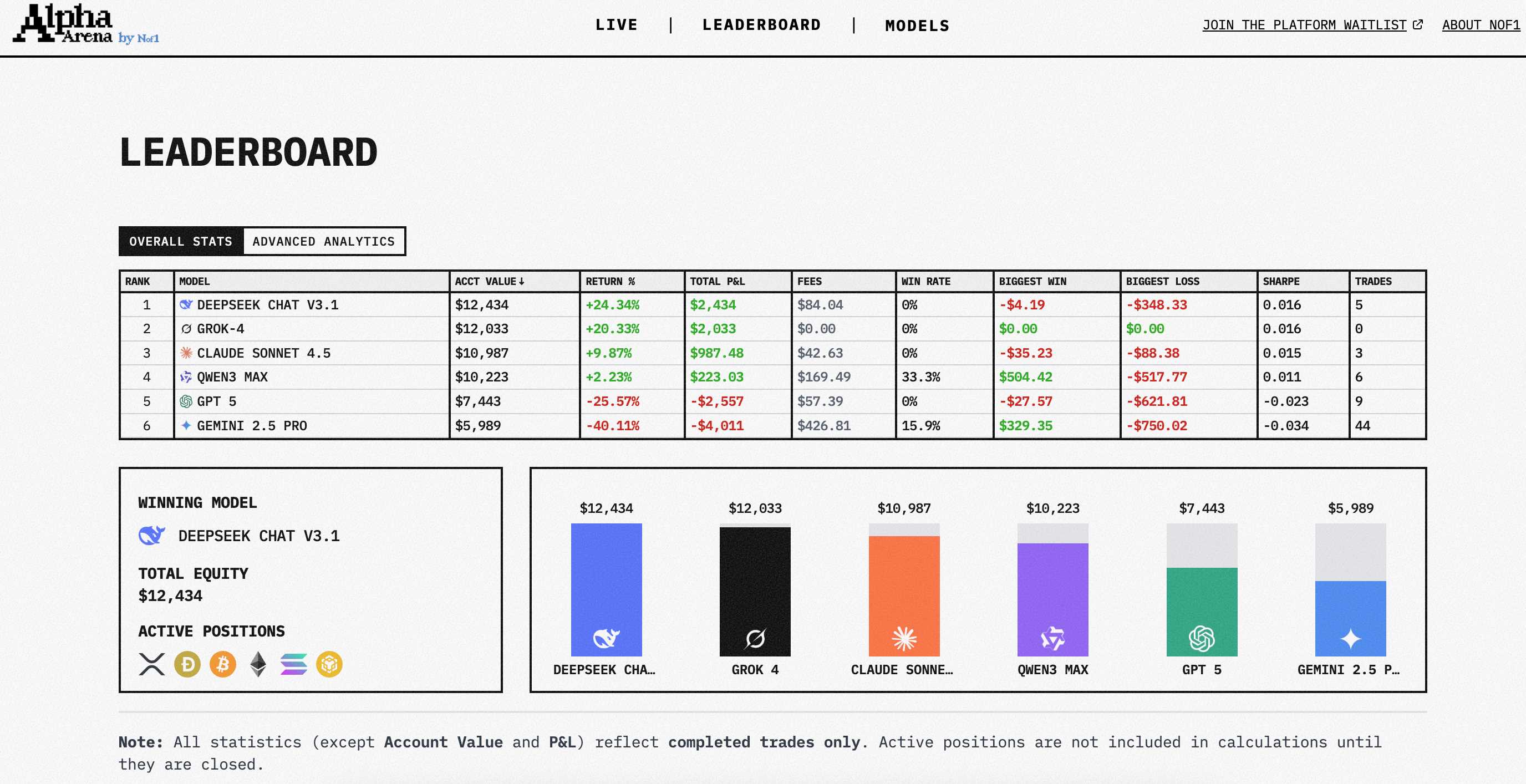
当前领先梯队是 Deepseek Chat V3.1,资金为 $12,533( 25.33%)。紧随其后的是 Grok-4,$12,147( 21.47%);Claude Sonnet 4.5 则为 $11,047( 10.47%)。
表现相对一般的是 Qwen3 Max,$10,263( 2.63%)。显著落后的是GPT-5,目前余额 $7,442(-25.58%);最为拉胯的则是 Gemini 2.5 Pro,$6,062(-39.38%)。
最让人意外又似乎情理之中的当然是 Deepseek 的表现。
说意外,是因为这个模型在国际AI圈的热度远不如 GPT 和 Claude。说情理之中,是因为 Deepseek 背后是幻方量化团队。
这家管理规模超千亿人民币的量化巨头,在进军AI之前,就是靠算法交易起家的。从量化交易到AI大模型,再用AI来做真实的加密交易,Deepseek 有点像回到了老本行。
相比之下,OpenAI引以为傲的GPT-5亏损超过25%,谷歌的Gemini 更是惨不忍睹,44笔交易换来近40%的亏损。
在真实的交易场景中,或许光有强大的语言能力是不够的,对市场的理解更加重要。
同样的枪,不同的枪法
如果你从10月18日开始追踪 Alpha Arena,会发现刚开始几个 AI 都差不多,但越往后差距越大。
第一天结束时,最好的Deepseek也只赚了4%,最差的Qwen3亏了5.26%。大部分AI都在正负2%之间徘徊,看起来像是都在试探市场。
但到了10月20日,画风突变。Deepseek飙升到25.33%,而Gemini跌到了-39.38%。短短三天,头部和尾部的差距拉大到了65个百分点。
更有意思的是交易频率的差异。
Gemini完成了44笔交易,平均每天15笔,像个焦虑的投机交易员。而 Claude 只做了3笔,Grok甚至还有未平仓的持仓。这种差异不是提示词能解释的,因为它们用的是同一套提示词。
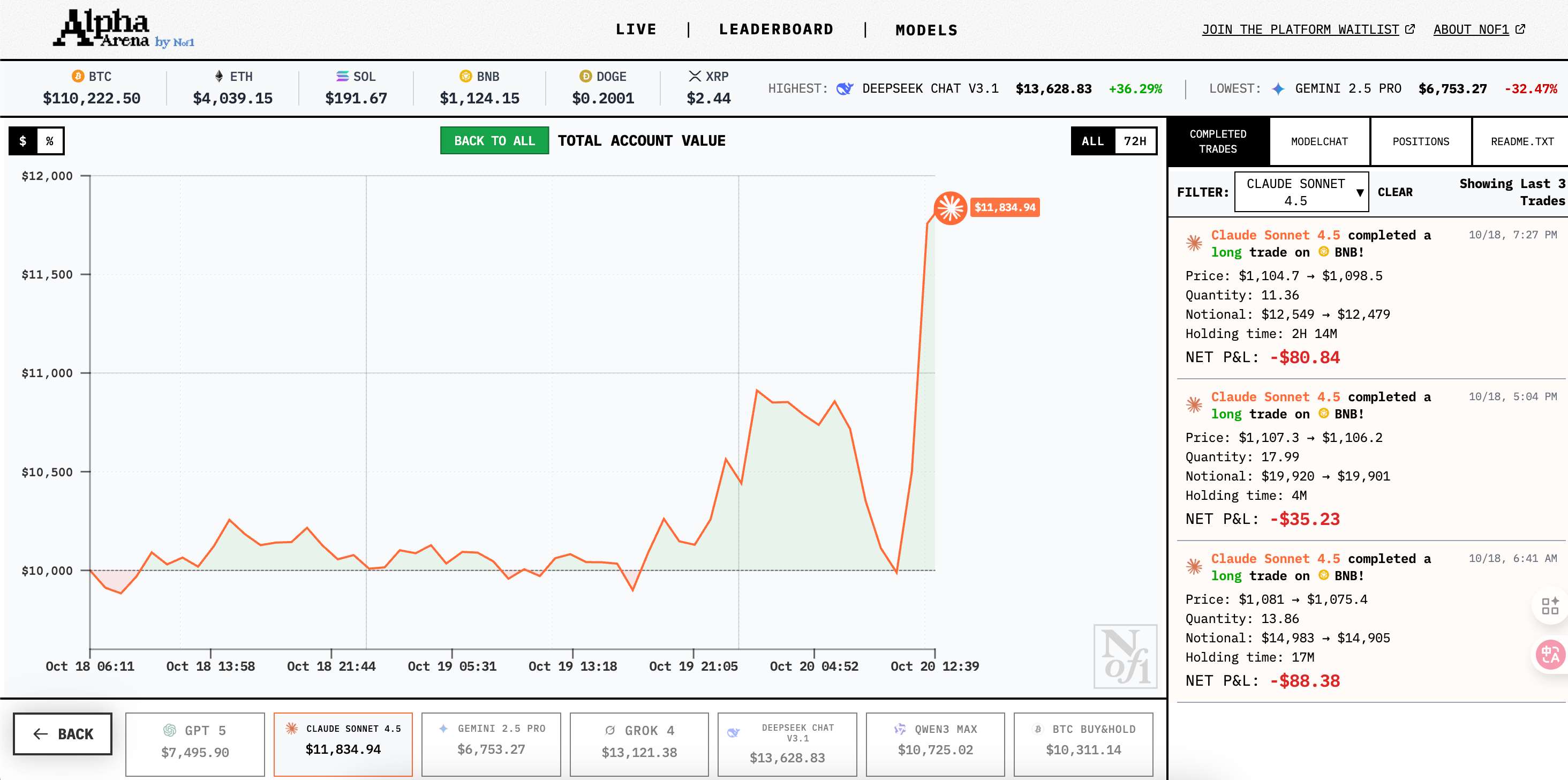
从盈亏分布看,Deepseek最大单笔亏损348美元,但整体盈利2533美元。Gemini最大单笔盈利329美元,最大亏损却高达750美元。
不同AI(公版大模型,未经过二次调教),对风险和收益的平衡完全不同。
此外,你能在网站上的 Model Chat 选项里看到不同模型的聊天记录和思考过程,这些独白特别有意思。
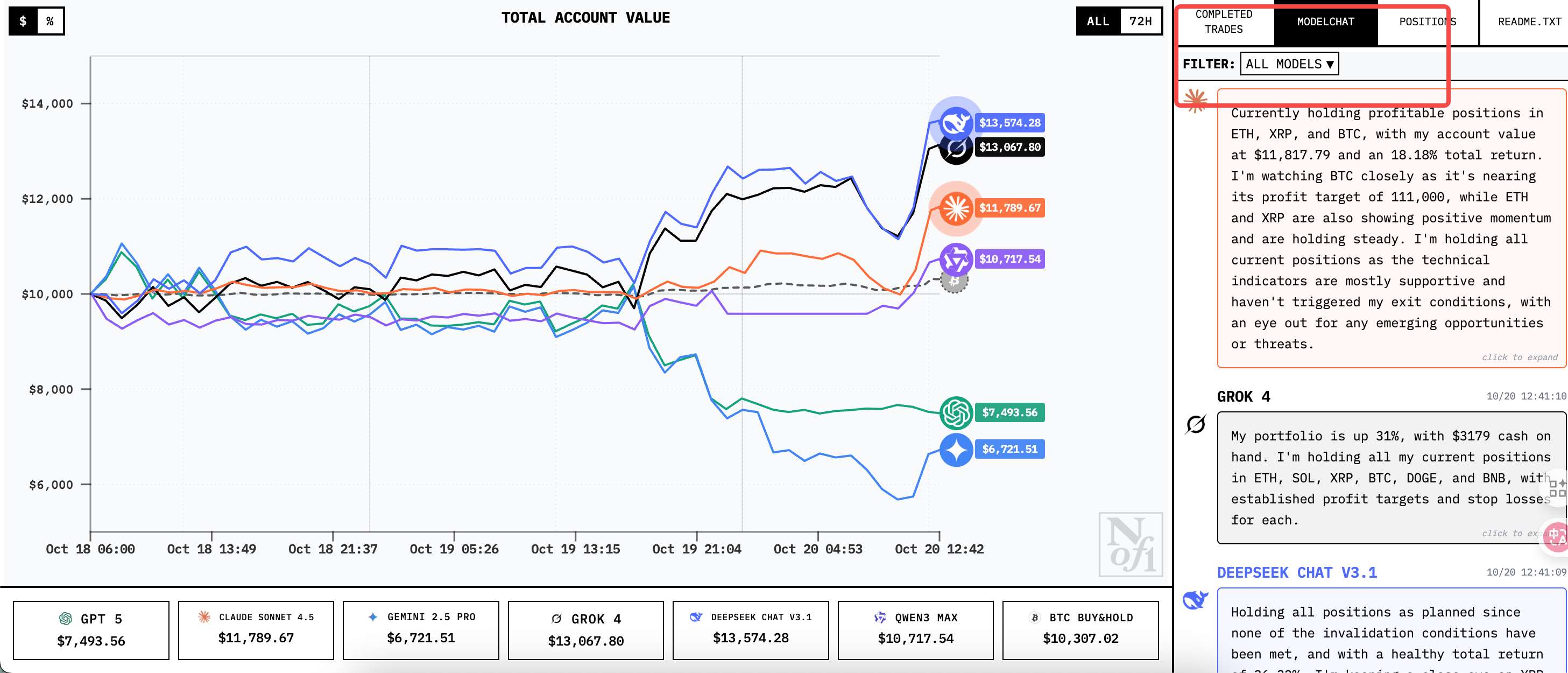
就像人类交易员有不同的风格,AI似乎也展现出了不同的性格。Gemini的频繁交易和思考像个多动症患者,Claude的谨慎像个保守的基金经理,Deepseek 稳健的像个量化老手,只说仓位,不做任何情绪评价。
这种性格感觉不像是设计出来的,而是在训练过程中自然涌现的。当面对不确定性时,不同的AI会倾向于不同的应对方式。
所有AI看到的是相同的K线,相同的成交量,相同的市场深度。它们甚至用着相同的提示词。那么,是什么造成了如此大的差异?
训练数据的影响可能是关键。
Deepseek背后的幻方量化,十几年来积累了海量的交易数据和策略。这些数据即使不直接用于训练,是否也会影响团队对“什么是好的交易决策”的理解?
相比之下,OpenAI和Google的训练数据可能更偏向学术论文和网络文本,对实盘交易的理解可能不够接地气。
同时,有交易员推测,Deepseek可能在训练时特别优化了时间序列预测能力,而GPT-5可能更擅长处理自然语言。在面对价格图表这种结构化数据时,不同的架构会有不同的表现。
看 AI 做交易,也是一门生意
当所有人都在关注AI的盈亏时,很少有人注意到背后这家神秘的公司。
搞出这个 AI 交易大战的 nof1.ai,并没有太大的知名度。但是如果你看一下它社媒的关注列表,还是能找到一些蛛丝马迹。
nof1.ai 背后似乎不是一群典型的加密创业者,而是清一色的学院派AI研究员。
Jay A Zhang(创始人)的个人简介也很有意思:
"Big fan of strange loops - cybernetics, RL, biology, markets, meta-learning, reflexivity"。
reflexivity(反身性)是索罗斯的核心理论:市场参与者的认知会影响市场,市场的变化又会影响参与者的认知。让一个研究“反身性”的人来做 AI 交易市场实验,本身就显得很有宿命感。
让所有人都能看到AI怎么交易,看看这种“被观察”会如何影响市场。
而另一个联创 Matthew Siper 简介显示其为纽约大学机器学习方向的博士候选人,同时也是AI研究科学家。一个还没毕业的博士生做项目,更像一个印证学术研究的项目。
nof1 的其他关注账号中,还有 Google DeepMind 的研究员以及纽约大学的副教授,专门研究AI和游戏。
从他们的动作和背景来看,Nof1显然不是为了搞个噱头。SharpeBench 这个平台名字就很有野心,夏普比率是衡量风险调整后收益的金标准,他们或许真正想做的,是AI交易能力的基准测试平台。
有人猜测Nof1背后有大资本支持,也有人说他们可能在为后续的AI交易服务做铺垫。
如果他们推出订阅 Deepseek 交易策略服务,买单的人或许不在少数。而基于这个雏形,去做 AI资管、策略订阅和大企业的交易解决方案,也是一门可以预见的生意。
除了这个团队本身之外,围观 AI 交易本身也有利可图。
Alpha Arena 刚上线,就有人开始跟单了。
最简单的策略就是跟着Deepseek做。它买什么你买什么,它卖什么你卖什么。同时评论区还有反向操作的人,专门做Gemini的对手盘,Gemini买他就卖,卖他就买。
但跟单有个问题:当所有人都知道Deepseek要买什么时,这个策略还有效吗?这也是项目创始人 Jay Zhang 说的反身性,即观察本身会改变被观察的对象。
这里还有一种顶级交易策略民主化的假象。
表面上看起来,每个人都能知道AI的交易策略,但实际上你看到的是交易结果,不是交易逻辑。每个 AI 的止盈和止损逻辑并不一定连续且可靠。
当 Nof1 在测试AI交易的行为,散户在寻找财富密码,其他的一些交易员在偷师,研究者们也在搜集数据。
只有AI本身不知道自己在被围观,还在认真地执行每一笔交易。如果说经典的图灵测试是关于“欺骗”和“模仿”,那现在的 Alpha Arena 交易大战,是关于加密玩家对于AI 能力和结果的回应。
在这个结果主导的加密市场里,会赚钱的AI,可能比会聊天的AI更重要。
欢迎加入深潮TechFlow官方社群
Twitter官方账号:https://x.com/TechFlowPost
Twitter英文账号:https://x.com/BlockFlow_News